Creating a simple, containerized Semantic Movie search with sentence-BERT
Published:
Semantic Movie Search
 As I recently discussed in another blog post, I’ve been having a lot of fun working with sentence-BERT (SBERT) to power intelligent semantic search systems that I develop at work. To demonstrate using SBERT in action, I decided to create a personal project that uses SBERT as the core of a semantic search system. The result is my new project, Semantic Movie Search, a simple site that lets you search for movies by describing what you want to see.
As I recently discussed in another blog post, I’ve been having a lot of fun working with sentence-BERT (SBERT) to power intelligent semantic search systems that I develop at work. To demonstrate using SBERT in action, I decided to create a personal project that uses SBERT as the core of a semantic search system. The result is my new project, Semantic Movie Search, a simple site that lets you search for movies by describing what you want to see.
Motivation
The inspiration for this project came from the many conversations I’ve had during the pandemic with my girlfriend when we were trying to pick a movie to watch. After the usual back and forth of asking each other what the other wants to watch, one of us would inevitably end up describing the kind of movie we want to watch. “I don’t know, just something relaxing and funny” she would say, “I’m feeling a drama, maybe a period piece” I might respond. What now? Does relaxing and funny mean searching through comedies, or could we find a drama that’s also funny and relaxing? A semantic search system could use these fuzzy descriptions of the type of movie we want to see to provide recommendations of movies that are semantically similar to our descriptions.
The Data
This seemed like a perfect problem for a semantic search system. But how do we embed the movies? What description do we use? I decided to solve this problem by aggregating user reviews of movies from IMDB. The idea is that user reviews on IMDB often use very descriptive language and read like a synopsis of the movie itself. For example, user reviews for Shawshank Redemption contain statements like “a poignant story about hope,” “ two inmates who become friends and find solace,” and “ tenacity, patience and wits.”
To gather this data, I scraped the IMDB website, gathering reviews for the top 500 movies, by rating, with at least 10,000 ratings, on the site. For each movie, I sampled five reviews. Certainly, five is no magic number, I just chose it because scraping the site (and later in the process, generating embeddings) takes time, and five reviews seems to sufficiently capture subjective and objective information about the movie. After cleaning up the data, I stored it in a SQLite database, and saved compressed versions of the data as parquet files. The code for scraping the website can be found in this notebook.
You may be asking - wait, aren’t there troves of movie review datasets already available? Why would you bother scraping the data yourself? Most of the data sets I found were designed for sentiment analysis tasks. As such, the user reviews were either not labelled with an associated movie title, or the reviews were selected for conveying some sentiment toward the movie. I needed a collection of descriptive reviews, associated with the original movie they came from.
Design
The application itself consists of a simple Vue.js search UI and a containerized Flask API with one primary POST endpoint for search requests. The movie data is stored in a SQLite DB and SQLAlchemy is used as the object-relational mapper (ORM).
For the model, I used the pre-trained SBERT stsb-distilbert-base model which is trained to score the semantic similarity of sentences using the cosine similarity of their embeddings. Note that there are many other viable options here, such as the stsb-mpnet-base-v2 model, which is a larger model, but it boasts better performance on benchmark datasets. For each movie in the dataset, the five reviews I sampled for the movie are encoded using the model into 768-dimensional embeddings. These five review embeddings are then pooled by averaging them. I then normalize this embedding (which I’ll discuss shortly), and the resulting embedding is the final movie embedding.
Once the movie embeddings are computed, I save them as a numpy file, along with a numpy array embedding_idx_to_movie_id that serves as an embedding index to movie ID look-up.
When the API is built, it creates a Faiss index using the pre-computed movie embeddings. It also loads the stsb-distilbert-base model. When a search request is received, the search text is embedded using the SBERT model. The Faiss index we created is then used to find the k nearest movies to the query embedding, where k is specified by the request.

The script above is the entirety of what I had to implement in the backend to serve a full semantic search (even the tokenization is handled by the SentenceTransformer API).
The only thing to call out here is that I’m using the faiss.IndexFlatIP index, and I’m normalizing the embeddings. This index computes inner products (or dot products) to measure distance between vectors (as opposed to L2-distance). The model is designed to compare sentences via cosine similarity, and, recalling some linear algebra, for two vectors A,B, we have that <A,B> = |A||B|Cos(A,B), where <> represents the inner product. Then, when we normalize our embeddings, we have |A| = |B| = 1, so <A,B> = Cos(A,B). Then this set-up is equivalent to computing the cosine similarity between embeddings.
Exploring the Results
I didn’t set this project up in a way that I’d have labelled data to evaluate the performance of the model for our task, but we can explore the results ourselves and visualize the embeddings! In general, the search results seem surprisingly good, especially since there was no fine-tuning for the task.
Vizualizing the embeddings
I quickly put together a notebook for visualizing the embeddings. I performed dimensionality reduction on the embedding data using t-SNE, projecting the data down to two dimensions. I then used K-Means clustering to identify 15 clusters. According to the wikipedia article about movie genres, there are about 13 primary movie genres, plus an “other/alternative” genre. So, adding a wildcard cluster, I arrived at 15 clusters as an educated guess. In the future, I plan on applying a more rigorous approach to this clustering by using a mixture model and an evaluation metric (e.g. BIC criterion) to select the number of clusters.
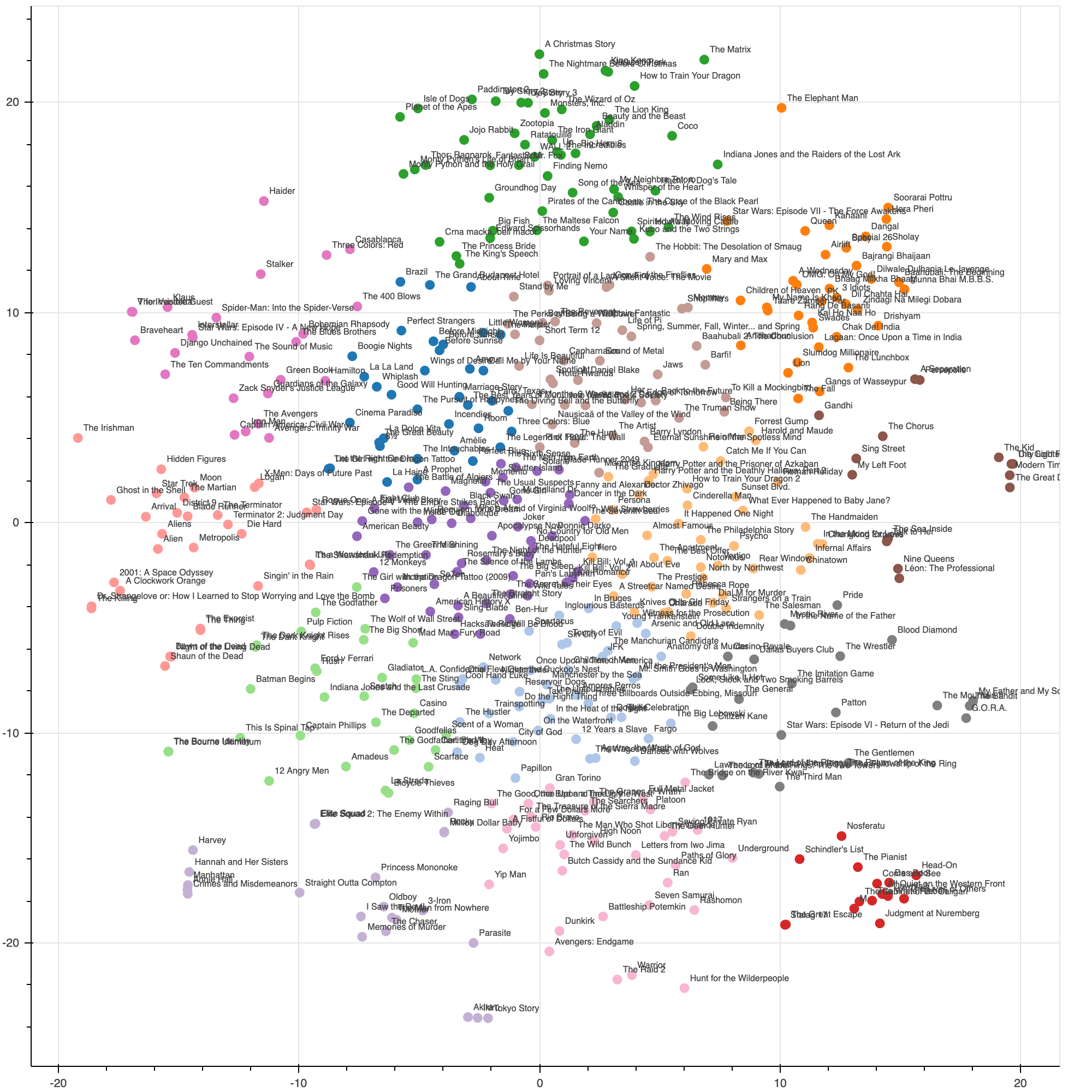 A visualization of the 500 movie embeddings
A visualization of the 500 movie embeddings
Trying to interpret the features captured by the embedding, it is clear that one vital dimension is the seriousness of the movie.
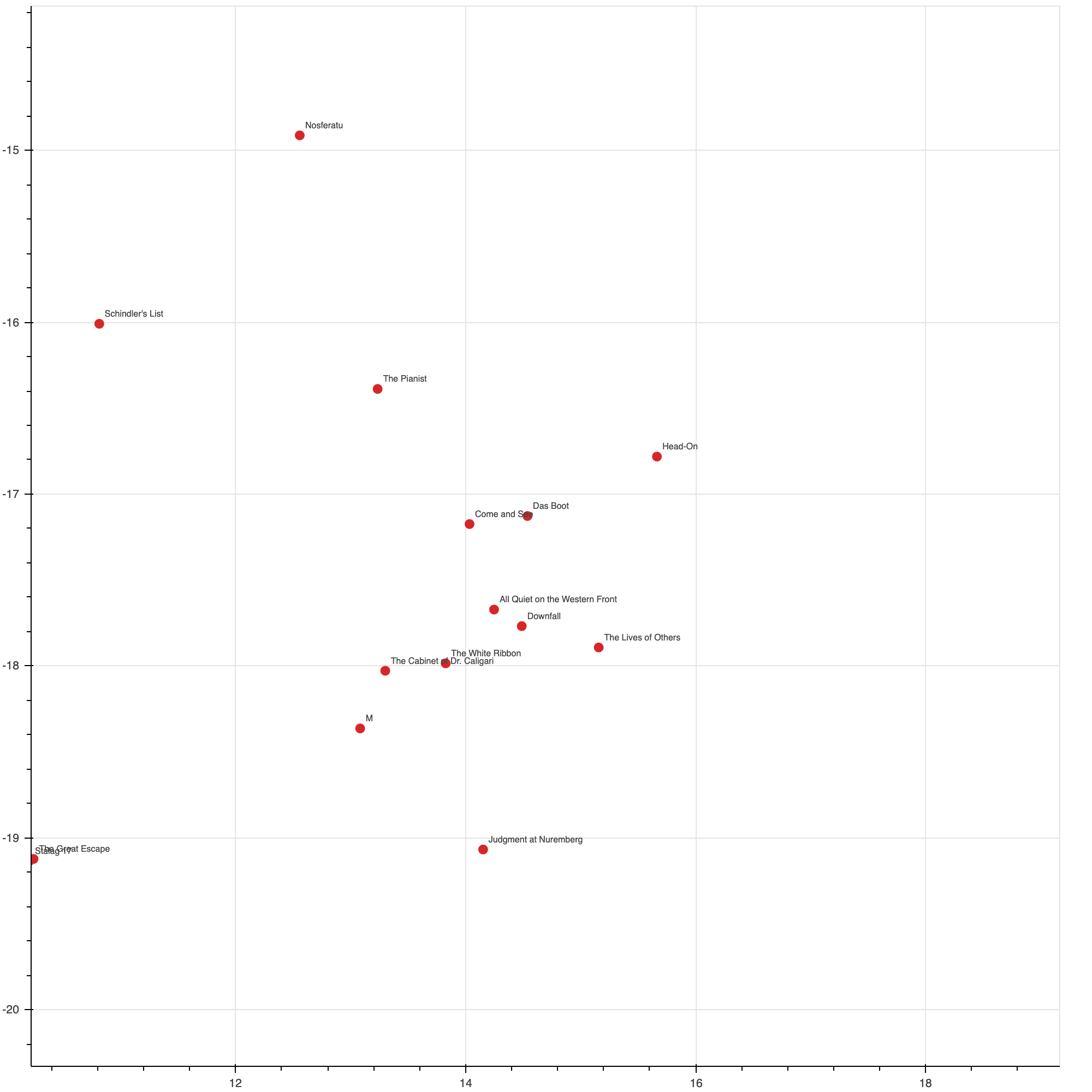
This cluster of films have the most negative values for one of the dimensions, and they are all incredibly serious, stoich, and sad films. In contrast, we have:

The cluster shown above have some of the most positive values for that dimension. Clearly, all these films are fun, relaxed, kid’s movies.
The other dimension is harder to interpret. It seems to have something to do with how ‘fictional’ or ‘fantastical’ the movie is - whether it is based on real people, or is perhaps a story that could occur in real life, versus fantasty stories including sci-fi and superhero movies (and lots of Tarantino movies).
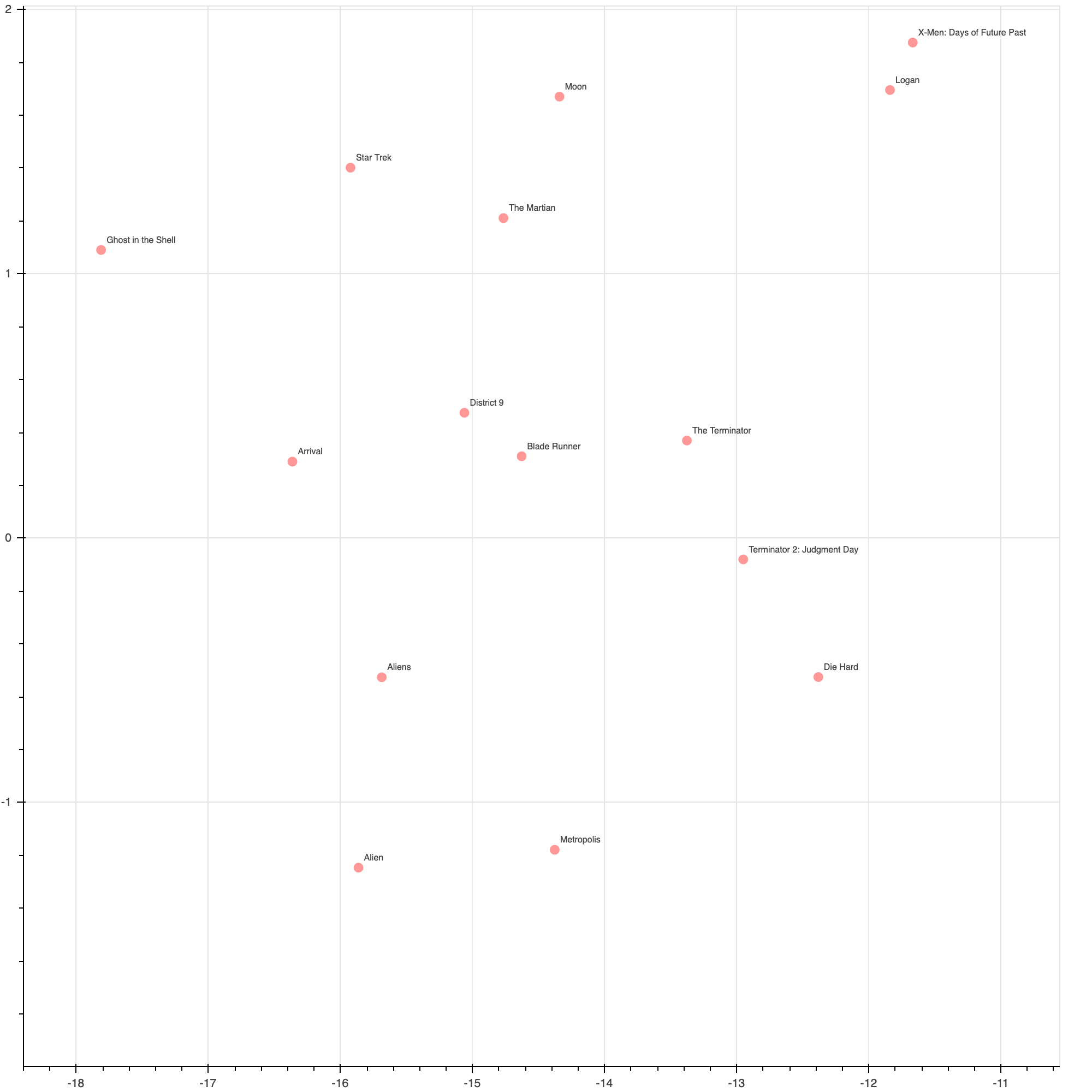 This orange cluster on one extreme of this dimension, clearly contains lots of sci-fi fantasy movies
This orange cluster on one extreme of this dimension, clearly contains lots of sci-fi fantasy movies
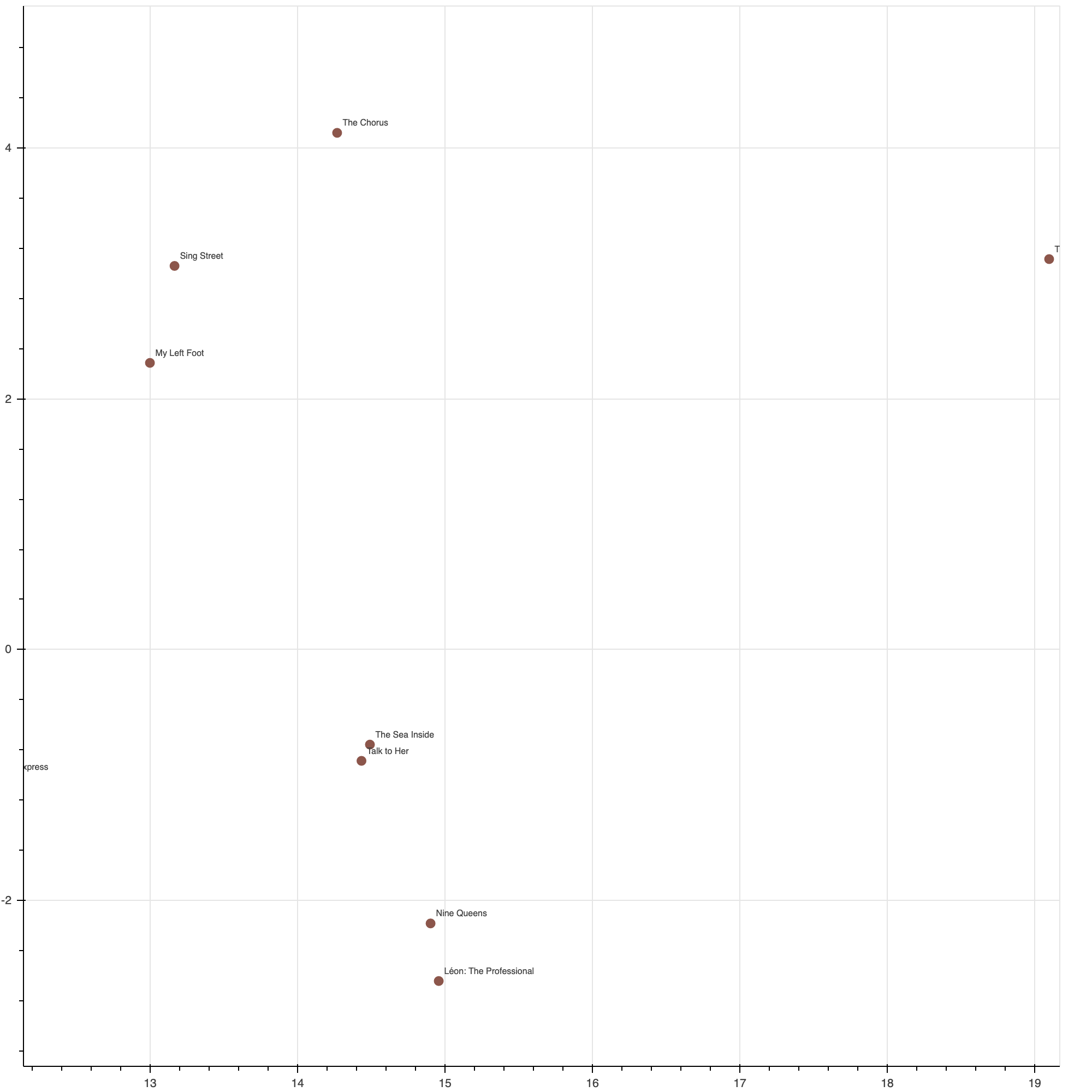 This brown cluster contains more ‘grounded’ movies that deal with more realistic aspects of human life, here on earth.
This brown cluster contains more ‘grounded’ movies that deal with more realistic aspects of human life, here on earth.
Some of the clusters identified are very interpretable, such as fantasy/sci-fi, bollywood, war, and thrillers. While there are certainly more direct and effective methods of clustering films and labelling them by genre, I think it is remarkable that such nice clusters can be found based solely on audience reviews.
Testing some queries
Below, I show a few example searches, to give a sense for the performance of this design.

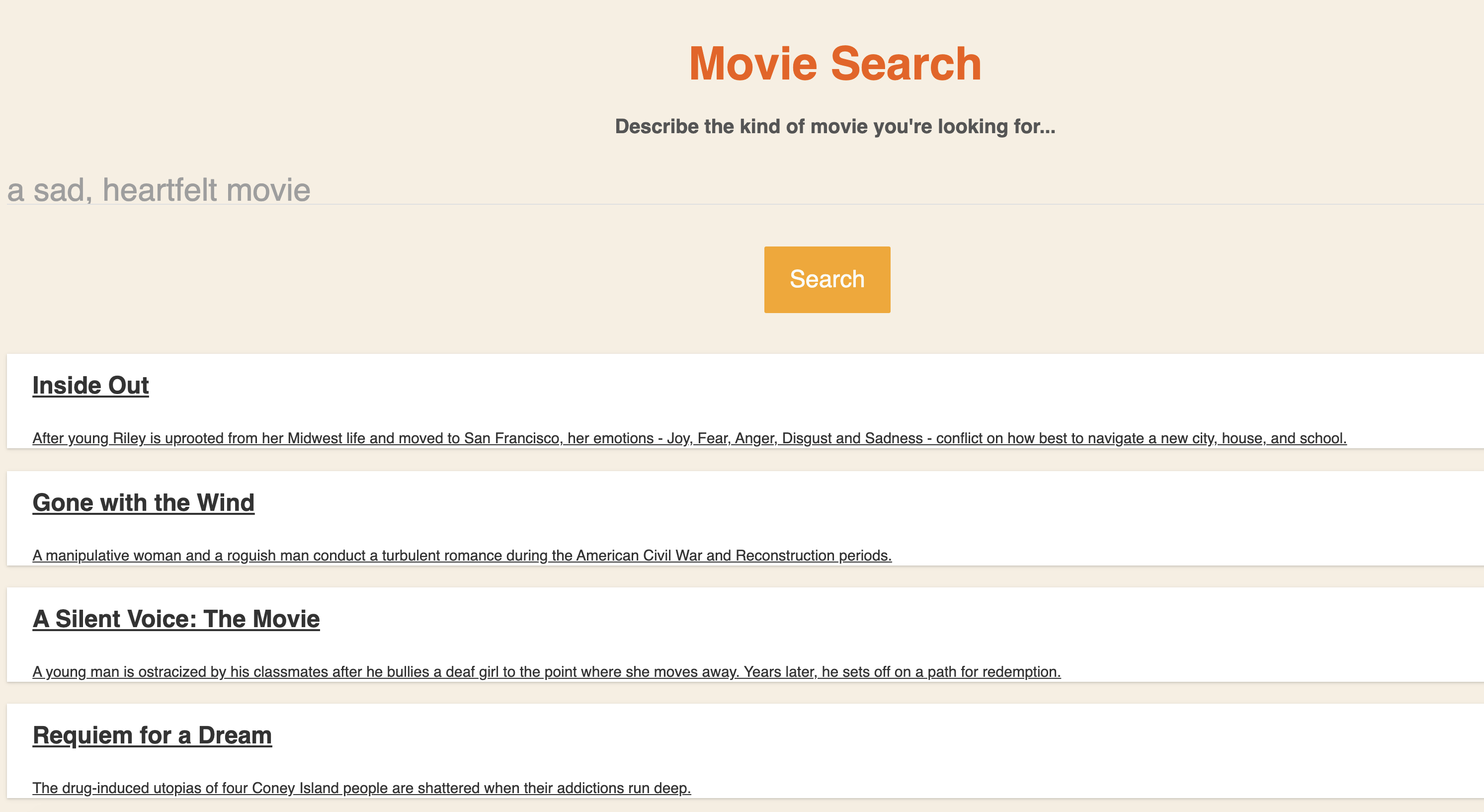

Given that there was no fine-tuning at all, these results seem very impressive. For almost every ad-hoc search I’ve tried myself, there has been at least one relevant movie in the top 5 returned. In the last search there are some results that are not exactly what I described (Indiana Jones is certianly not a gangster movie), but perhaps they are related in some ways. And the fourth result, Snatch, matches my description perfectly. Seriously, Snatch is a hilarious gangster movie, check it out if you haven’t.
Going Forward
I’m really happy with the results of this experiment. The model performs well, the API and the UI are simple and functional, and it has actually helped me pick out new movies to watch! In the future, I plan to put up some new blog posts with updates on this project, perhaps after trying some new models and doing some fine-tuning. Stay tuned!