
Sentence-BERT In Production: Early Experiments
Published:
Sentence-BERT In Production
At work, much of my time has been devoted to developing an intelligent search based web application. While there are plans to commercialize this application, it is currently an internal service, so for the purposes of my blogging I will leave out the specifics.

As a recent college grad, I was aware of the gap that exists between state of the art research and industry applications. This is not a knock on either, but I knew that the various research topics I had explored in college were likely inefficient, unruly, or otherwise impractical for the real world applications I would be developing in industry. I write this blog post to highlight one remarkable exception to this notion - sentence-BERT, which originally appeared here in 2019, less than two years ago. This class of models has been implemented effectively as an easy to use API that can be employed immediately as a semantic search service.
What does sentence-BERT offer?
In short, sentence-BERT can be thought of as an extension of the BERT model specifically designed for efficiently finding semantically similar sentences. As stated in the abstract of the original sentence-BERT paper
BERT (Devlin et al., 2018)… has set a new state-of-the-art performance on sentence-pair regression tasks like semantic textual similarity (STS). However, it requires that both sentences are fed into the network, which causes a massive computational overhead: Finding the most similar pair in a collection of 10,000 sentences requires about 50 million inference computations (~65 hours) with BERT.
Clearly, BERT is not designed for search. The intelligent search projects I work on are precisely based on finding similar pairs of documents in a collection of tens of thousands of documents, so it is unsurprising then that we did not use BERT for our search methods. Enter sentence-BERT:
Sentence-BERT (SBERT), (is) a modification of the pretrained BERT network that use siamese and triplet network structures to derive semantically meaningful sentence embeddings that can be compared using cosine-similarity. This reduces the effort for finding the most similar pair (of sentences) from 65 hours with BERT / RoBERTa to about 5 seconds with SBERT, while maintaining the accuracy from BERT.
And that’s the bottom line: pre-trained sentence-BERT models provide sentence embeddings where the semantic similarity of sentences can be compared using cosine similarity, and this can be done very efficiently.
The One-Two Punch of Sentence-Transformers + Faiss
In another post, I go into detail showing just how easy it can be to get started with sentence-BERT models and using them as the core of a search or recommendation system, so I won’t belabor the point here (but make sure to check out that post!). Rather than telling you how easy it is, let me show it in the code snippet below with less than 10 lines of code. 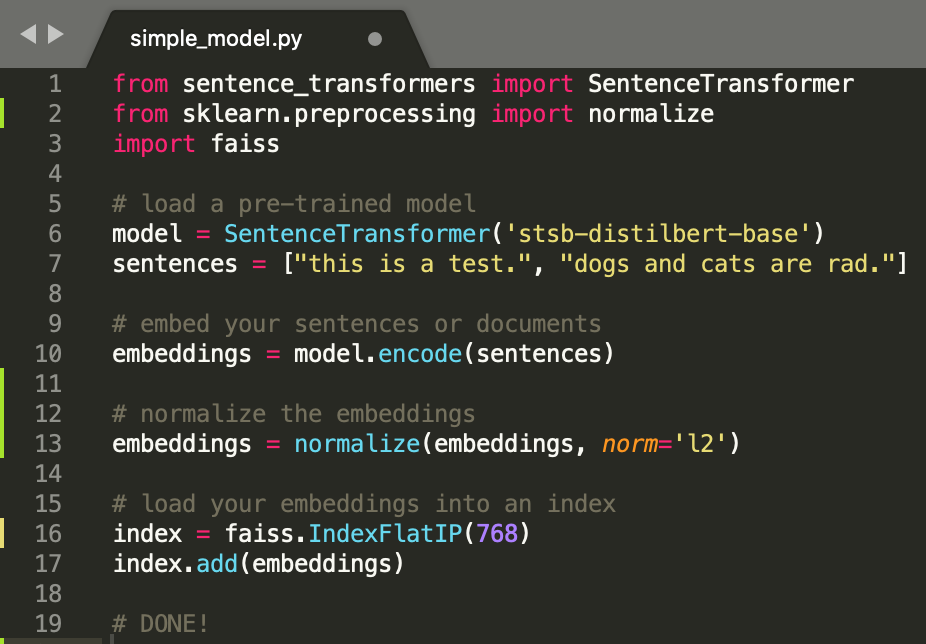
You can check out the Faiss library here, but in short it provides an index for storing vector embeddings along with a function to efficiently search through the stored embeddings using either L2 distance or dot product vector comparison. SBERT is designed to measure the similarity of senteces via cosine similarity, so by normalizing the embeddings and searching using inner product comparisons, we are in fact searching by cosine similarity.
With your corpus embeddings added to the index, all that’s left is to search! For example, if your service receives a search query, you can embed the query text using the encode method, then find the k-nearest neighbors in your corpus with index.search(query_embedding, k)
That’s really all there is to working with a pre-trained SBERT model. Even the tokenization is handled for you! Okay, I’ll stop going on about it :)
The Ease of Fine-tuning (when necessary)
With their wide array of pre-trained models that generalize exceedingly well to many different search and translation tasks, what comes out-of-the-box from the Sentence-Transformers library often works great without the need for any fine tuning. I have found in my work, however, that sometimes fine-tuning these models is necessary depending on the task.
In my work experience, I have found that the pre-trained models work great if you
- Have documents with common language (or language similar to that used to train the model)
- are primarily concerned with a task that one of the (many) pre-trained models were trained for
For example, if you have a Q&A system, and you want the user to ask a question and have the system search for similar questions, a great starting point would be the quora-distilbert-base pre-trained model, which was fine tuned on Quora duplicate question data.
On the other hand, you may want to consider fine-tuning one of these models if:
- Your data is highly specific to your domain and uses domain-specific language
- “Similar” documents in your corpus are not necessarily semantically similar or follow a common pattern.
For the application I work on, fine-tuning has been a necessity. The language of the documents in our corpus is very specific to the domain, and the task is not exactly to find semantically similar documents. Rather, we are mapping from documents of type A to documents of type B, and it may be that a document b of type B may be the most semantically similar to some document a of type A, but b is not actually associated with a.
I want to avoid this post reading like a tutorial, so I will instead reference the fine-tuning documentation here, and provide a code snippet from their documentation below.

All you need to do is pick a Loss function, load your data, and call the fit method. There are more options, including seamless multi-objective training. We use this to quickly and easily train a single model to associate documents of type A with those of type B, and additionally learn associations between documents of type C and documents of type B. Again, it is not that multi-objective training is anything ground-breaking, but the API makes the process simple and efficient, which is really helpful for rapid testing and development in production.
Fine-tuning SBERT models when necessary is both efficient and simple, and can lead to significant performance improvement. In my case, I have applied SBERT to problems where the accuracy of the pre-trained model was in the single digits (around 8%), and fine-tuning lifted the accuracy up to over 70%, which outperformed any model that had been previously deployed.
For ranking tasks, you can further refine your system by using another model, such as a cross-encoder model, to re-rank search results. The cross-encoder models tend to outperform the standard bi-encoder SBERT models, but score pairs of sentences individually, making these models ineffecient for searching through large sets of data. I have not applied this technique to re-rank search results in my work, mainly because it hasn’t been necessary, but it’s a potentially useful option to get some additional lift.
In summary
I am amazed at how quickly SBERT is being taken up by industry, and how easy it has been to pick it up, test it out, and deploy it to a production system in a matter of months! Check out my personal movie search project to see how you can create a simple search application with SBERT in a matter of hours.
If you made it this far, thank you for taking the time to read through this! I’m hoping to make a series discussing my adventures with production ML, especially NLP applications, and the various tools, tricks, and tech I explore along the way!
 As I recently discussed in
As I recently discussed in